AI #1 - Gemma Developer Day
This series of posts discusses news and changes in the field of AI.
Today, we will focus on the Gemma Developer Day in Paris, where google announced the release of Gemma 3, the newest multi modal language models in their “open weights” lineup.
Despite a lot of corporate speak and hedging, the talks covered genuinely interesting technical and industry insights. This post will cover the main features of the new models and other interesting announcements and insights. Let’s get to it.

Index
- Small Model, Big Performance
- Technical Highlights
- HuggingFace Transformers And Low Cost Robotics
- Jetson Shenanigans
- Concluding
Small Model, Big Performance
The largest model in the Gemma 3 series, the 27 Billion parameter model, rivals OpenAI, XAI and DeepSeek models roughly 20 times its size, at least according to the Chatbot Arena benchmark.
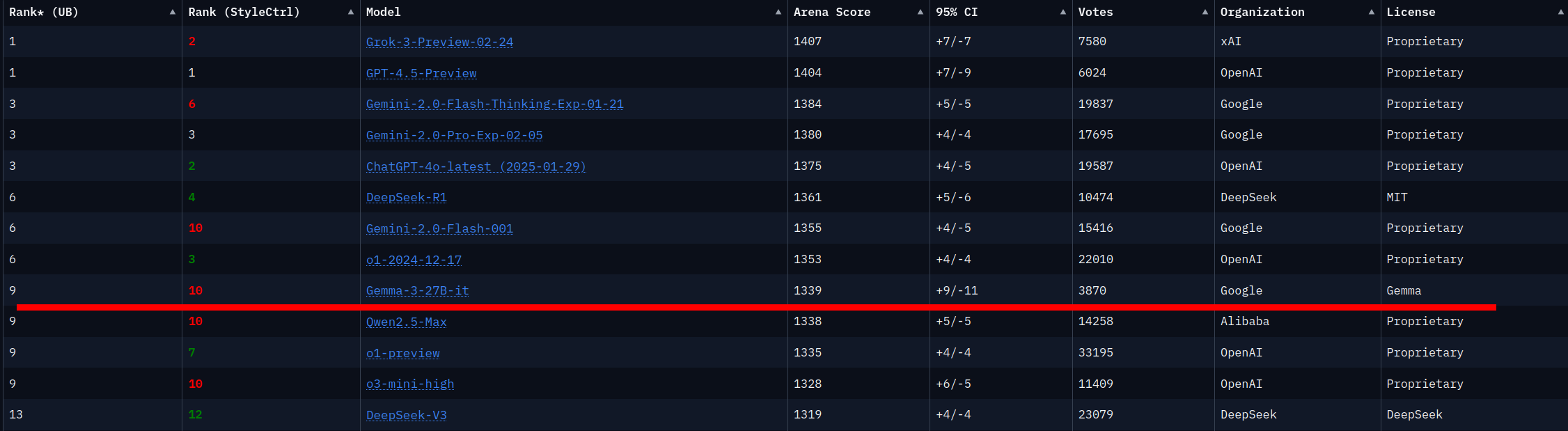
More performance can apparently be compressed into way fewer parameters.
The smaller size makes the models much more accessible to programmers, hackers and researchers, the difference being that instead of a compute cluster you now need a beefy desktop to run these models yourself.
In this release cycle the Gemma team pitched a few key features:
- Multilingual models: The models tout much better broad language performance across 140 languages. As I understand it, they do not only focus on translation, but also try to include cultural nuances and differences into the training data.
- Multi modal inputs: Excluding the smallest model, all models support text and image inputs. You can even include short videos frame by frame as image data.
- Large context: The smallest model can handle up to 32k context (100 pages), the other models up to 128k (400 pages or 500 images). Technically the models can handle more context, but this turned out to be a good cutoff during development. These developments are consistent with Google’s focus on large context lengths currently boasted by the Gemini models.
In total the new release includes 4 model versions, with several quantization options each.
- Gemma3-1B: Smallest model, can run on most mobile phones (given small quantization). No image inputs or outputs, not suitable as a chatbot, but can recover information from text and summarize.
- Gemma3-4B: Slightly larger model, can run on many laptops. Has image inputs as well as text input. Somewhat better as chatbot, but not great.
- Gemma3-12B: Everything Gemma3-4B has, but with better performance at higher compute costs. If you have a heavy duty computer (macbook with plenty of unified memory) you might be able to run this locally.
- Gemma3-27B: Largest model with highest compute costs. Best performance and suitable as chatbot.
During the event I ran the 1B and 4B models on my laptop. It felt like the above holds true. The 1B model is not suitable to chat with, and the 4B model is also a bit clunky. They are very responsive though, even on relatively limited portable hardware.
Technical Highlights
The event had a pretty solid line-up of technical talks. Usually about 15 minutes in length, diving into technical aspects of the Gemma models. If you’d like a full reference you can read the technical report.
Conspicuous in its absence was any discussion on reasoning ability. There was no real opportunity to ask questions about that during the event either. The DeepSeek-R1 models and OpenAI deep research have made waves lately, so Google avoiding the topic might mean they missed the boat this release cycle.
The team discussed two other models besides the Gemma 3 models.
First a model called ShieldGemma2, which classifies image and text inputs as “safe” or “unsafe” according to a flexible set of “curation policies”. I don’t like calling this a “safety” model, because what this model does is much more accurately described as censorship. Marketing aside there are clear use cases for message curation. Let’s not confuse censorship with safety though.
The second was PaliGemma2, an impressive vision-language model (VLM), which can take both text and images as input. Capable of doing segmentation and classification through a special set of tokens, this model blurs the boundaries between specialized models and the VLM approach to image processing. Gemma 3 models also have vision capabilities, although they lack these special tokens for classification and segmentation.
Watermarking text so it can be recognized as “AI generated” is now also possible through SynthID. The ideas struck me as clever, and I hadn’t been exposed to viable watermarking approaches before, although I have not searched for them either. The user generating the text still needs to choose to watermark text as generated by AI, so it is not a bullet-proof method to detect generated text generally.
HuggingFace Transformers And Low Cost Robotics
Hugging Face presented two interesting talks, one on how models are integrated into their transformers library, and one on their (low cost) robotics library LeRobot. The key takeaway is that Hugging Face is building open source projects that make model deployment and robotics way more accessible. I especially appreciated Remi Cadene, the presenter of the LeRobot talk, addressing the need for more research on topics like safety as progress on robotics continues. One of the few speakers at the event daring to directly address the safety elephant in the room.

Jetson Shenanigans
Everyone at the event got a Jetson Orin Nano to experiment with running Gemma models on a small compute device (a bribe perhaps, but at least a good one), so of course there was a talk about that. In true demo fashion the video did not work, so they presented Gemma3-4B running on the Jetson live. Impressive to see the progress on running local models on a small 25-Whatt device handling both text and image inputs. For reference, most lightbulbs take more energy to run.
Concluding
Google seems intent to push their open weight models further, trying to solidify its position by delivering good multilingual support and long contexts. Critical discussion on critical features like reasoning and safety is (perhaps obviously but sadly) lacking, only addressing surface level issues, insisting on trust regardless. Still, the Gemma team seems to be pushing some impressive technological innovations, with seemingly plenty of room to improve the models further.